
I’ve been having a fair bit of trouble with this week’s part of the course. I asked if anyone had any tips and encountered a few others on the course who are also struggling. The general advice is to just copy the notebook and change the bits that are necessary. This is fine – and it works – but this doesn’t help me learn what the code is actually doing (and I’m pretty sure that doesn’t solve all of the exercises). So while I’d like to do that, having thought about it yesterday, I don’t think I’m going to. I’m probably going to get frustrated again before I finish, but I am determined to finish.
Starting over again from the beginning of week 4, I notice the explanation of the use of a question mark to provide more information about the usage of a particular function (it doesn’t work for methods so I’ll use the documentation on the pandas website to help with pandas methods). I’ll be making use of that as I go through (and I probably should have been doing so anyway). It also would have been helpful to know about this at the beginning of the course, but hey ho. I will go back over my blog entries next week and update them if necessary if they’re incorrect.
I worked through the first few pages quite quickly. These were mostly reading, and little code.
Getting and Storing Data via an API
As I mentioned previously, this week I’m comparing subsets of data within a data set using the Comtrade website.
After importing the pandas module, you can use the Comtrade website’s API to save the details you want to a dataframe. You use the following code to do this:
URL='http://comtrade.un.org/api/get?max=5000&type=C&freq=A&px=HS&ps=2014%2C2013%2C2012&r=826&p=all&rg=all&cc=0401%2C0402&fmt=csv'
df=read_csv(URL, dtype={'Commodity Code':str, 'Reporter Code':str})
To get the link for the data you want to look at, use the Comtrade website to find it, preview your query, and then click the link for the API call (at the bottom of the page). To get it in the right format for pandas to work with, you’ll then have to add &fmt=csv on the end. This is saved as the constant URL. The rest of the code uses the read_csv() method to get the data from the link you just found (URL), change some of the data types to strings (dtype={'Commodity Code':str, 'Reporter Code':str}) and then saves this as a dataframe called df.
| Classification | Year | … | FOB Trade Value (US$) | Flag | |
|---|---|---|---|---|---|
| 0 | HS | 2014 | … | NaN | 0 |
| 1 | HS | 2014 | … | NaN | 0 |
| 2 | HS | 2014 | … | NaN | 0 |
The data you get from Comtrade is extensive, so you will probably want to cut it down to just the data you are interested in. To do this use the following code:
COLUMNS = ['Year', 'Period','Trade Flow','Reporter','Partner', 'Commodity','Commodity Code','Trade Value (US$)'] df=df[COLUMNS]
This names the constant COLUMNS and adds to it the column names 'Year', 'Period','Trade Flow','Reporter','Partner', 'Commodity','Commodity Code','Trade Value (US$)'. The next line of code states for the dataframe df to use these columns only, and then updates the df dataframe accordingly.
| Year | Period | Trade Flow | … | Commodity | Commodity Code | Trade Value (US$) | |
|---|---|---|---|---|---|---|---|
| 0 | 2014 | 201401 | Exports | … | Wheat or meslin flour | 1101 | 66847 |
| 1 | 2014 | 201401 | Exports | … | Wheat or meslin flour | 1101 | 5829 |
As the data from Comtrade includes worldwide data cumulatively and also includes data for the separate countries, it is worth making two datasets to work with that take this into account. The following code does splits the dataset using comparison operators:
world = df[df['Partner'] == 'World'] countries = df[df['Partner'] != 'World']
A new dataframe called world is made, where the df dataframe has been filtered to only show entries where the 'Partner' column contains the word 'World'. Another dataframe is set up, this one called countries. This new dataframe will list all rows where the 'Partner' column does not match the word 'World'.
You can then save this to a file so you’re not having to query the website all the time through the code countries.to_csv('saved_data_example.csv', index=False) to specify that the dataframe stored as countries should be saved to a file named saved_data_example.csv. To read from the file you saved, you would then use the read_csv() method as before only now use the file name instead of a URL. I also had to add , encoding = "ISO-8859-1" as the data file was saved with a type of encoding that the pandas module can’t read by default.
Split-Apply-Combine
Split
As I explained previously, the course goes into the split-apply-combine pattern. You can split the data simply as we have done already, using comparison operators, or by grouping it. Grouping takes a dataframe and based on the column names you specify, takes all the unique entries from those columns and puts them together. Now, I’m pretty sure this is no longer a dataframe once you’ve grouped it. Checking the pandas documentation, they refer to it as a GroupBy object. So this might be the reason why I was struggling so much before – using the wrong methods on the wrong object type.
To make a group, you use the groupby() function: grouped_countries = countries.groupby('Trade Flow'). This makes a groupby object called grouped_countries that takes the countries dataframe and groups its content by the 'Trade Flow' column. If you want to use multiple columns, you can. Simply use grouped_countries = countries.groupby( ['Trade Flow','Commodity Code','Year']) instead.
You can use the get_group() function to display the data for a specific group: grouped_countries.get_group('Imports'). This displays all entries from the group grouped_countries that match 'Imports'. You can see the groups available for you to choose from with grouped_countries.groups.keys() (note that grouped_countries.groups will show all of the keys, and all of the entries within those keys, within the group object).
You can sort grouped data with the sort() method. The code grouped_countries.get_group('Imports').sort("Trade Value (US$)", ascending=False) will list all the entries in the group 'Imports' sorted with the highest Trade Value (US$) at the top (.sort("Trade Value (US$)", ascending=False)). When you have a group with multiple entries, use .get_group(('Exports','1104',2014)) instead (so, get a group that has 'Exports' as the 'Trade Flow', '1104' as the 'Commodity Code' and 2014 as the year. Note the '' are used to denote strings, numbers do not have '' around them (remember the code when we made the dataframe specified that 'Commodity Code' should be treated as a string).
Apply
Summary
Summary is performed by the aggregate() function that can take sum, min, max and mean. Sum adds all of the contents of a group; min will find the minimum value; max will find the maximum value; and mean will provide the average of the numbers by adding them and dividing by the total. For example, the code countries.groupby('Commodity Code')['Trade Value (US$)'].aggregate(sum) takes the dataframe countries, groups it by 'Commodity Code' and then summarises it by adding the contents of the 'Trade Value (US$)' column together for every unique entry in the 'Commodity Code' column. Also, you can apply the summary to a group directly if you’ve named it: grouped_countries['Trade Value (US$)'].aggregate(sum).
You can have multiple summaries with .aggregate([sum, min, max, mean]) (I don’t think pandas works with mean by default though. It looks like the exercise book imported a module called numpy to do this).
If you want to use multiple columns you can also do that. Simply specify those columns in the groupby() method: grouped_countries.groupby(['Commodity','Trade Flow','Year'])['Trade Value (US$)'].aggregate([sum, min, max, mean]). This would give a table like below:
| Commodity | Trade Flow | Year | sum | min | max | mean |
|---|---|---|---|---|---|---|
| Commodity 1 | Exports | 2014 | 40215103 | 5 | 8908460 | 693363 |
| Commodity 1 | Exports | 2015 | 32298379 | 2 | 9634586 | 633301 |
| Commodity 1 | Imports | 2014 | 30423330 | 932 | 8020014 | 2535277 |
| Commodity 1 | Imports | 2015 | 20614513 | 1427 | 6494426 | 1717876 |
| Commodity 2 | Exports | 2014 | 46923551 | 20 | 32069689 | 1303431 |
| Commodity 2 | Exports | 2015 | 40191337 | 15 | 30336727 | 1148323 |
| Commodity 2 | Imports | 2014 | 21950746 | 68 | 10676138 | 1688518 |
| Commodity 2 | Imports | 2015 | 18685554 | 12 | 10091544 | 1334682 |
As well as the aggregate() function, you can also define your own functions and use the apply() function to use them on your group.
def top2byAmount(g):
return g.sort('Amount', ascending=False).head(2)
grouped_countries.apply(top2byAmount)
The above would define a function called top2byAmount that takes a group input (g) and sorts it by the ‘Amount’ column in descending order (.sort('Amount', ascending=False)), returning the top two values (head(2)). The new function is then applied to the grouped_countries group.
Filter
The filter() method – which is similar to apply() in that it takes the name of a filter that you have previously defined – can be used as so:
def groupsWithValueGreaterThanFive(g):
return g['Value'].sum() > 5
df.groupby('Commodity Code').filter(groupsWithValueGreaterThanFive)
The above code defines a filter called groupsWithValueGreaterThanFive that takes a group (g), and returns anything from the 'Value' column that has a sum greater than 5 (return g['Value'].sum() > 5). You can then apply this filter (.filter(groupsWithValueGreaterThanFive)) to a dataframe called df that is grouped by the 'Commodity Code' column (df.groupby('Commodity Code')).
The aggregate() method can also be used to filter contents, but this time with len (which counts the number of records in each group). You can also use len().
You can combine these two methods into one. For example:
def weakpartner(g): return len(g)<=3 | g['Trade Value (US$)'].sum()<25000
The above code defines a filter that intends to find countries that do not trade very often. The filter is called weakpartner and it takes a group (g), and returns any rows where the number of rows is less than or equal to 3 (len(g)<=3) – there are 3 or less entries for each unique group – or (|) the sum of each group’s Trade Value is less than $20,000 (g['Trade Value (US$)'].sum()<25000).
Pivot Tables
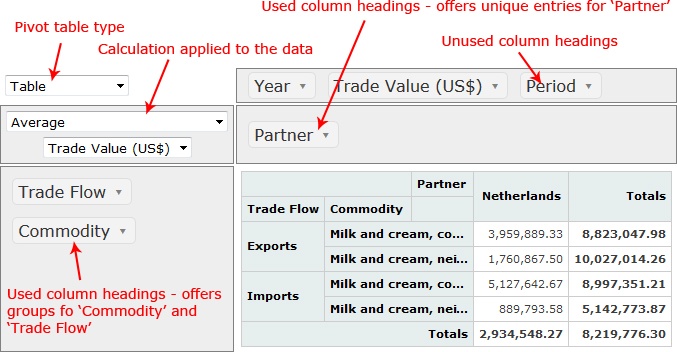
A pivot table allows you to summarise data by grouping it by columns, and then applying a filter to other columns to make a new range of data. Spreadsheet packages offer pivot tables usually, but in this case I’m using an interactive web-based version.
In terms of split-apply-combine, pivot tables split your data into groups, and apply filters.
In a pivot table you can specify several of your original column headings on the left side to act as the new groups (in the example to the right, this is the Trade Flow and Commodity headings), and then specify other column headings at the top of the pivot table to add unique groups (in the example I chose the Partner heading). Applying a filter such as the average of the Trade Value (US$) column will give you a table showing the average trade value for exports in both milk commodities for all partners. It will also give you the total for each row and each column.
Pandas can do pivot tables for Jupyter, but these aren’t interactive like the one I used above. You do this through the pivot_table() function. Setting an index parameter gives you the row categories, the columns parameter gives you the column categories, the values parameter gives the filter category, and the aggfunc parameter states what filter you are using. So, the code:
pivot_table(df,
index=['Commodity','Partner'],
columns=['Trade Flow'],
values='Amount',
aggfunc=sum)
Would set up a pivot table called df, that has the row categories of 'Commodity' and 'Partner', a column category of 'Trade Flow', and a filter that adds up all the unique entries in the 'Amount' column (values='Amount', aggfunc=sum). Adding the code , margins=True will add the totals to the end of each row and column as shown previously in the interactive pivot table.
Combine
Combine didn’t seem to be explained, so I’m assuming that is the use of both the split and apply parts together. So you ‘combine’ the ‘split’ and ‘apply’ techniques.
If I wanted to show all of the partners that traded both ways (import and export) for over $1,000,000 I would need to first define a filter called partnerImportExportHigh that discarded anything under that value.
def partnerImportExportHigh(g): return g['Trade Value (US$)'].sum()>=1000000
Then I would make a new group called grouped_countries that was the countries dataframe grouped by the 'Period', 'Trade Flow', 'Commodity Code' and 'Partner' headings. I’d then apply the filter to this new group.
grouped_countries=countries.groupby(['Period','Trade Flow','Commodity Code','Partner']).filter(partnerImportExportHigh)
Finally I’d make a pivot table from the grouped_countries group, called report. This would have the row categories as 'Period' and 'Partner', and the column category as 'Trade Flow'. It would also filter these according to their total 'Trade Value (US$)'. To remove countries with only one-way trades I’d apply the dropna() function to the report.
report=pivot_table(grouped_countries, index=['Period','Partner'], columns='Trade Flow', values='Trade Value (US$)', aggfunc=sum) report.dropna()
The pivot table will now show for each month, any countries with an import and export value of over $1,000,000 for all commodities.
| Period | Partner | Exports | Imports |
|---|---|---|---|
| 201401 | France | 1328775 | 2341411 |
| 201401 | Ireland | 8018979 | 1332402 |
| 201402 | France | 1285386 | 3718166 |
| 201402 | Ireland | 7432263 | 2240515 |
| 201402 | Netherlands | 1307499 | 6275146 |
| 201403 | France | 1394541 | 2299340 |
| 201403 | Netherlands | 1444004 | 6483203 |
| 201404 | France | 1127810 | 4040008 |
| 201404 | Ireland | 8201888 | 1133782 |
| 201405 | Ireland | 9739506 | 1199553 |
| 201406 | France | 2503897 | 5012027 |
| 201406 | Ireland | 9217423 | 3408952 |
| 201407 | France | 1010838 | 1464206 |
| 201408 | France | 1266387 | 1493152 |
| 201408 | Ireland | 7418375 | 1608985 |
| 201409 | France | 1121055 | 1349927 |
| 201410 | France | 1164837 | 1142580 |
| 201410 | Ireland | 8690336 | 1706296 |
| 201410 | Netherlands | 1791473 | 2080063 |
| 201411 | France | 1198330 | 2122182 |
| 201412 | Ireland | 7544667 | 5781875 |
Graphs
The course pages themselves didn’t go into graphs, but the exercise book did, so I’m including that here.
The code grouped_countries['Trade Value (US$)'].aggregate(sum).plot(kind='barh') would make a horizontal bar graph (barh) from the grouped_countries group with 'Trade Value (US$)' as the x axis.
You can sort the order of the bars if you want, either by adding inplace=False parameter to your sort() or using the order() function. The code below gives both examples:
countries_grouped.sort('Trade Value (US$)',inplace=False,ascending=False).head(5).plot(kind='barh')
countries_grouped.order('Trade Value (US$)',ascending=False).head(5).plot(kind='barh')
Project
For the project, we were asked to take a commodity and write a report on how well it performed for the United Kingdom in terms of import and exports over this year. The data available was only from January to August, so when I was asked to compare this to the same period in 2014, I had to remove a few months of data. I went a bit further with my project than I probably needed to, but the data I chose to look at – fish products such as frozen, cured, etc. – didn’t quite work with the example given.
You can see a copy of my project notebook here.
Terms
These terms are written as I understand them.